Publication Highlights
Speech Emotion Recognition in the Wild using Multi-task and Adversarial Learning
Interspeech 2022
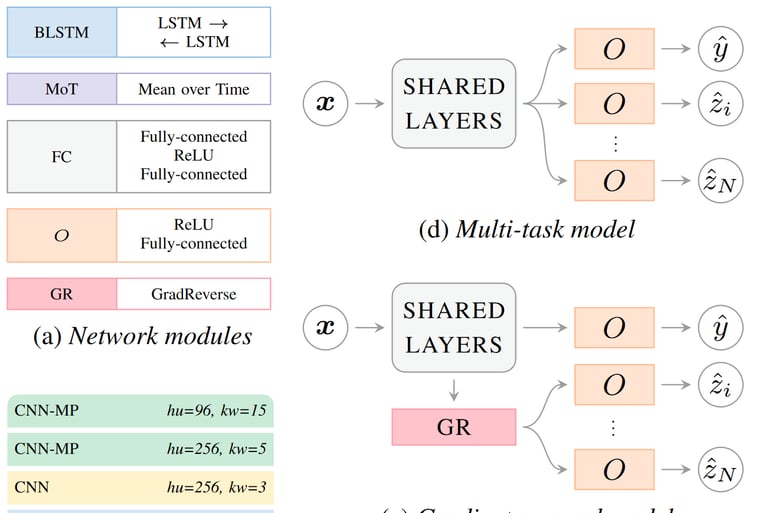
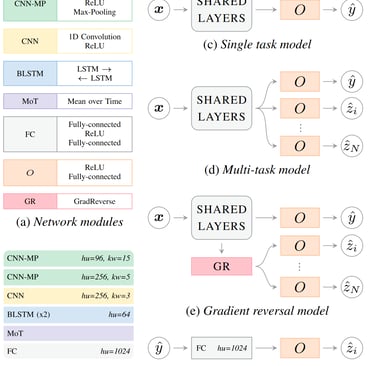
Speech Emotion Recognition (SER) is an important and challenging task, especially when deploying systems in the wild i.e. on unseen data, as they tend to generalise poorly. One promising approach to improve the generalisation capabilities of SER systems is to incorporate attributes of the speech signal, such as corpus or speaker information, which can be a source of overfitting or confusion for the model. In this paper, we investigate using multi-task learning, where attribute prediction is given as an auxiliary task to the model, and adversarial learning, where the model is explicitly trained to incorrectly predict attributes. We compare two adversarial learning approaches: gradient reversal and an adversarial discriminator. We evaluate these approaches in a cross-corpus training setting using two unseen corpora as test sets. We use four attributes -- corpus, speaker, gender and language -- and evaluate all possible combinations of these attributes. We show that both multi-task learning and adversarial learning improve SER performance in the wild, with the gradient reversal approach being the most consistent across attributes and test sets.
Emotion Label Encoding Using Word Embeddings for Speech Emotion Recognition
Interspeech 2023
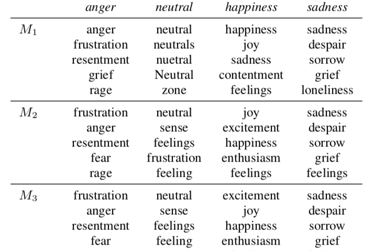
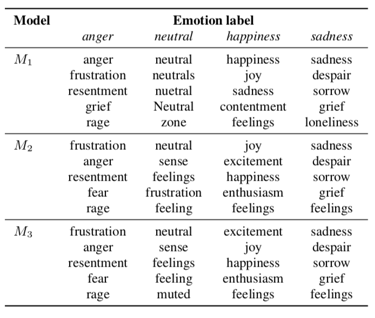
Speech Emotion Recognition (SER) is an important and challenging task for human-computer interaction. Human emotions are complex and nuanced, hence difficult to represent. The standard representations of emotions, categorical or continuous, tend to oversimplify the problem. Recently, the label encoding approach has been proposed, where vectors are used to represent the emotion space. In this paper, we hypothesise that using a pre-existing vector space that encodes semantic information about emotion is beneficial for the task. To this aim, we propose using word embeddings obtained from a Language Model (LM) as labels for SER. We evaluate the performance of the proposed approach on the IEMOCAP corpus and show that it yields better performance than a standard baseline. We also present a method to combine free text labels, which are unusable in conventional approaches, and by doing so we show that the model can learn more nuanced representations of emotions.
Full Publications List
E. Stanley, E. DeMattos, A. Klementiev, P. Ozimek, G. Clarke, M. Berger, and D. Palaz, D. Emotion Label Encoding Using Word Embeddings for Speech Emotion Recognition. Proceedings of Interspeech 2023, pp. 2418-2422. [pdf]
J. Parry, E. DeMattos, A. Klementiev, A. Ind, D. Morse-Kopp, G. Clarke, and D. Palaz. Speech Emotion Recognition in the Wild using Multi-task and Adversarial Learning. Proceedings of Interspeech 2022, pp. 1158-1162. [pdf]
S. Condron, G. Clarke, A. Klementiev, D. Morse-Kopp, J. Parry, D. Palaz, Non-Verbal Vocalisation and Laughter Detection Using Sequence-to-Sequence Models and Multi-Label Training, Proceedings of Interspeech 2021, pp. 2506-2510. [pdf]
J. Parry, D. Palaz, G. Clarke, P. Lecomte, R. Mead, M. Berger, G. Hofer, Analysis of Deep Learning Architectures for Cross-Corpus Speech Emotion Recognition, Proceedings of Interspeech 2019, pp. 1656-1660. [pdf]
D. Palaz, M. Magimai-Doss, R. Collobert, End-to-end acoustic modeling using convolutional neural networks for HMM-based automatic speech recognition, Speech Communication 108, pp. 15-32, 2019. [pdf]
D. Palaz, Towards end-to-end speech recognition, Ph.D. Thesis, EPFL, 2016. [pdf]
D. Palaz, G. Synnaeve, R. Collobert, Jointly Learning to Locate and Classify Words Using Convolutional Network, Proceedings of Interspeech 2016, pp. 2741-2745. [pdf]
D. Palaz, M. Magimai-Doss, R. Collobert, Convolutional neural networks-based continuous speech recognition using raw speech signal, Proceedings of ICASSP 2015. [pdf]
D. Palaz, M. Magimai-Doss, R. Collobert, Analysis of CNN-based Speech Recognition System using Raw Speech as Input, Proceedings of Interspeech 2015, pp. 11-15. [pdf]
D. Palaz, M. Magimai-Doss, R. Collobert, Learning linearly separable features for speech recognition using convolutional neural networks, ICLR 2015 workshop. [pdf]
D. Palaz, M. Magimai-Doss, R. Collobert, Joint phoneme segmentation inference and classification using CRFs, Proceedings of IEEE Global Conference on Signal and Information Processing (GlobalSIP) 2014. [pdf]
D. Palaz, R. Collobert, M. Magimai-Doss, End-to-end phoneme sequence recognition using convolutional neural networks, NIPS 2013 Deep Learning workshop. [pdf]
D. Palaz, R. Collobert, M. Magimai Doss, Estimating phoneme class conditional probabilities from raw speech signal using convolutional neural networks, Proceedings of Interspeech 2013, pp. 1766-1770. [pdf]
D. Palaz, I. Tošić, P. Frossard, Sparse stereo image coding with learned dictionaries, IEEE International Conference on Image Processing 2011, pp. 133-136.
M. Borgeaud, D. Palaz, P. Deleglise, Monitoring of Land Cover Charge Using SAR and Optical Data from the ESA Rolling Archives, Proceedings of ESA Living Planet Symposium, 2010.
